Java の文字型 (char)
Java の char は文字を表すプリミティブ・データタイプ
Java ではオブジェクトではない基本的なデータ型がいくつかあります。これを、プリミティブデータタイプ (primitive data types) といいます。
char は文字を表すプリミティブデータタイプであり、16ビットの整数型です。
| データ型 | 意味 | 既定値 |
|---|---|---|
| char | 16ビットの符号なし整数 0 から 65,535 までを表します。 | \u0000 |
同じ整数型のデータ型でも、数値を表すデータ型については「Java の整数型 (byte, short, int, long)」をみてください。
Java の char 型の既定値
char 型の場合も数値の場合と同様に、 0 が既定値になります。
初期化のルールも数値の場合と同様に、ローカル変数の場合は変数を使う前に初期化が必須です。クラスのフィールドの場合は、明示的に初期化していない場合は既定値が使われます。
Java の文字は Unicode
Java の文字型は Unicode UTF-16 エンコーディング
Java の文字型 (char) では、文字を Unicode として扱います。
Java の char 型は 2 バイト (16ビット) のデータ型です。しかし、Unicode の文字のコードポイント (符号位置) は U+0000 から U+10FFFF に割り当てられています。このため、必ずしも 2 バイトだけでは 1 文字を表すことができません。
2 バイトの文字型で文字を扱うために、Java ではエンコーディングルールとして UTF-16 を用います。
UTF-16 では 1 文字を 2 バイトまたは 4 バイトのいずれかで表します。このため、 U+0000 から U+10FFFF という広い範囲を扱うことができる上に、 「1 文字が 2 バイトか 4 バイト」であるので、2 バイトのデータ型である char でキリが良い形で使うことができます。
ひとことで言うと、BMP (基本多言語面) の文字を 2 バイトで表し、SMP (補助多言語面) をサロゲートペアの 4 バイトで表すということになります。
Unicode の UTF-16 エンコーディング手順
Unicode を UTF-16 でエンコーディング (符号化) するということは、どういうことか簡単に説明します。
コードポイント U+0000 から U+FFFFの範囲の UTF-16 符号化手順
Unicode でコードポイントが U+0000 から U+FFFF である範囲の文字は、Unicode のコードポイントそのものが UTF-16 の文字コードとして使われます。
例えば、文字 A の Unicode のコードポイントは U+0041 です。従って UTF-16 では 0x0041 と符号化されます。
符号は 2 バイトなので、Java の char 型のデータひとつで 1 文字になります。
コードポイント U+10000 から U+10FFFF の範囲の UTF-16 符号化手順
Unicode のコードポイントが U+10000 から U+10FFFF の文字は、下記の手順で 4 バイトに符号化します。
符号化の方法を具体例で説明します。次の Emoji の Unicode コードポイントは U+1F923 です。これを UTF-16 エンコーディングしてみましょう。

- Unicode コードポイント U+1F923 の数値から 0x10000 を引く。
0x1F923 - 0x10000 = 0xF923
- 上の結果 0xF923 を 0x400 で割る。
0xF923 / 0x400 = 0x3E 余り 0x123
- 0xD8 に、上の商 0x3E を足す。
0xD8 + 0x3E = 0xD83E
- 0xDC に、上の余り 0x123 を足す。
0xDC + 0x123 = 0xDD23
- 上の計算で得られた 0xD83E 0xDD23 を UTF-16 の符号とする。
このように計算することで、Unicode のコードポイント U+1F923 が UTF-16 における符号 0xD83E 0xDD23 となります。
この符号化の上位2バイト (この例では0xD83E)、下位2バイト(この例では 0xDD23) をそれぞれ、ハイサロゲート、ローサロゲートといいます。
Java の char 型の動作確認
Java のコードで動作を確認しましょう。
Java の char 型 1 個で1文字を表す場合
次のように char 型の変数に文字コードとして 0x0041 をセットすると、 確かに A として認識されます。
char ch = 0x0041;
System.out.println(ch); // AJava の char 型 2 個で1文字を表す場合
上で見たように Unicode コードポイント U+1F923 は UTF-16 で 0xD83E 0xDD23 になります。
次の例のように char の配列を用いて 2 個の char データに 4 バイト分の文字コードを書き込むことで、ひとつの Emoji U+1F923 を表現することができます。
char[] a = new char[2];
a[0] = 0xD83E;
a[1] = 0xDD23;
String s = new String(a);
System.out.println(s);実行結果は次の通りです。
逆に文字列に Emoji ひとつを文字列に書くと文字の長さは 2 と認識されます。
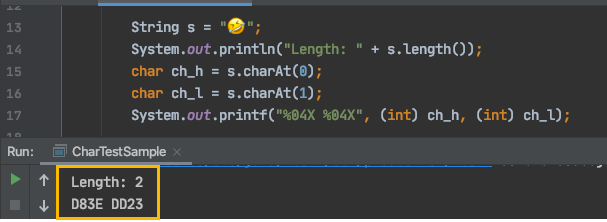
先頭の char、次の char を取り出して 16 進数で出力すると確かに D83E と DD23 として認識されていることがわかります。